Finding Climate Targets with LLMs, Part 4 - Pseudo-Agentic Approach
Implementing a pseudo-agentic framework for rapid RAG experimentation.
· 5 min read
Introduction #
I implemented a pseudo-agentic approach to improve the performance of the RAG system I introduced in my previous post. This resulted in a framework that enabled rapid experimentation, in parallel, for identifying performance constraints and testing hypothetical solutions.
In a short amount of time, I managed to run a large number of experiments in parallel and identified some key constraints, while achieving some small but meaningful improvements limited to a very tight budget.
Overall, using Codex effectively as a lab partner, I now have a clear path to experimentation and iterative improvements at a very fast rate of learning, running a number of experiments that might have taken weeks to complete otherwise. Relevant code and results are given in the repository linked at the end.
Approach #
I wanted to automate as much of the experimental discovery loop as possible. In this context, I mean the process of going through experimental ideas as quickly as possible, within this flow:
Idea → Hypothesis → Experiment → Analysis → Insight → Next Idea
Out of caution, I decided against an initial fully agentic approach and instead adopted a human-in-the-loop method in which I would have involvement during each step. This resulted from my need to understand the quality of “thinking” by the LLM before fully committing to it fully autonomously running operations.
In practice, this meant that I would used OpenAI Codex as a lab partner, helping me facilitate as much possible but never handing the reigns over fully. To begin, I devised an experimental strategy document to create both guidelines and guardrails for the project processes, along with the standard AGENTS.md file that Codex takes custom instructions from. The resulting EXPERIMENTAL_STRATEGY.md file covered the essential philosophy of how to conduct the project, ranging from scope to decision-making rules, including metrics. Codex adapted the code from the previous post in line with the strategy file.
The scope of experiments required that the dataset stays fixed and immutable. However, experiments could apply to the entire RAG architecture, including model changes. I had the constraint of a limited budget and prioritised experimental ideas accordingly.
I built a set of tools to faciliate the workflow, including a dashboard which is shown in Figure 1 below.
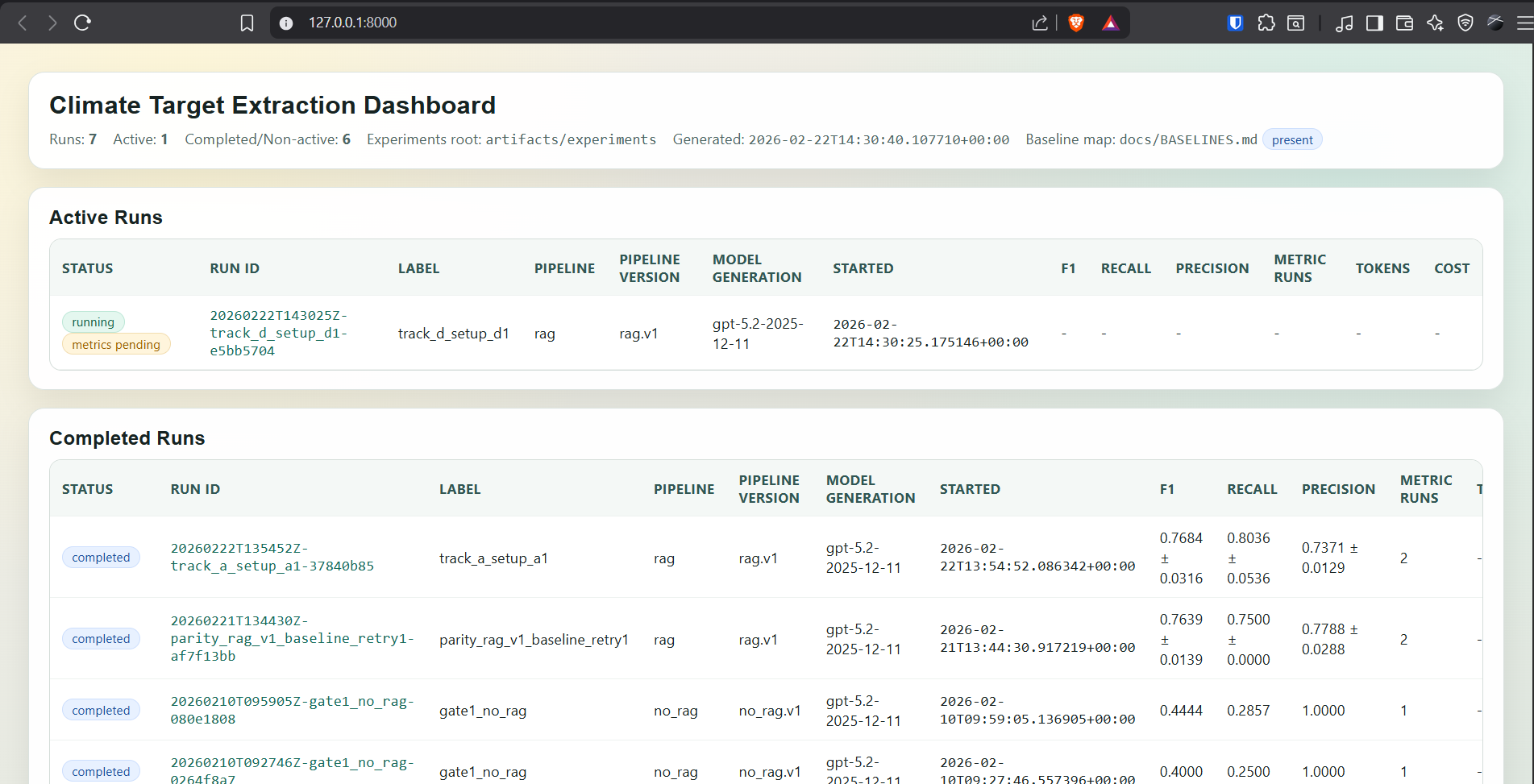
Learnings #
After the experimental framework was set, I perhaps managed in 24 hours to complete an amount of work that might have taken weeks otherwise. However, it fell short when it came to ideating and determining the most rewarding next step. It lacked true expert insight and could not get an adequate grip of cause and effect. I might be able to improve this via better prompting in the future.
I had prioritised my initial experiments by anticipated reward-to-cost in order to find improvements with the least increase in unit cost. Needless to say, negative findings counted as much as positive ones in this learning process. I tried a wide range of ideas in a short amount of time, including changing prompts, RAG parameters, sentence transformer re-ranking and combining the results of multiple runs. Most of the time, these improved recall but at the cost of precision and were thus rejected. All findings are documented in the repo in the file called PROJECT_LEARNINGS_2026-03-02.md.
Diving into the results, coupled with my previous experience applying RAG to this domain, led to the hypothesis that better conversion of PDF to text would produce the highest gains. Figure 2 below gives a sample of how relevant information can be distributed across a relatively complicated layout, and if the conversion process does not account for this, it can affect both precision and recall markedly.
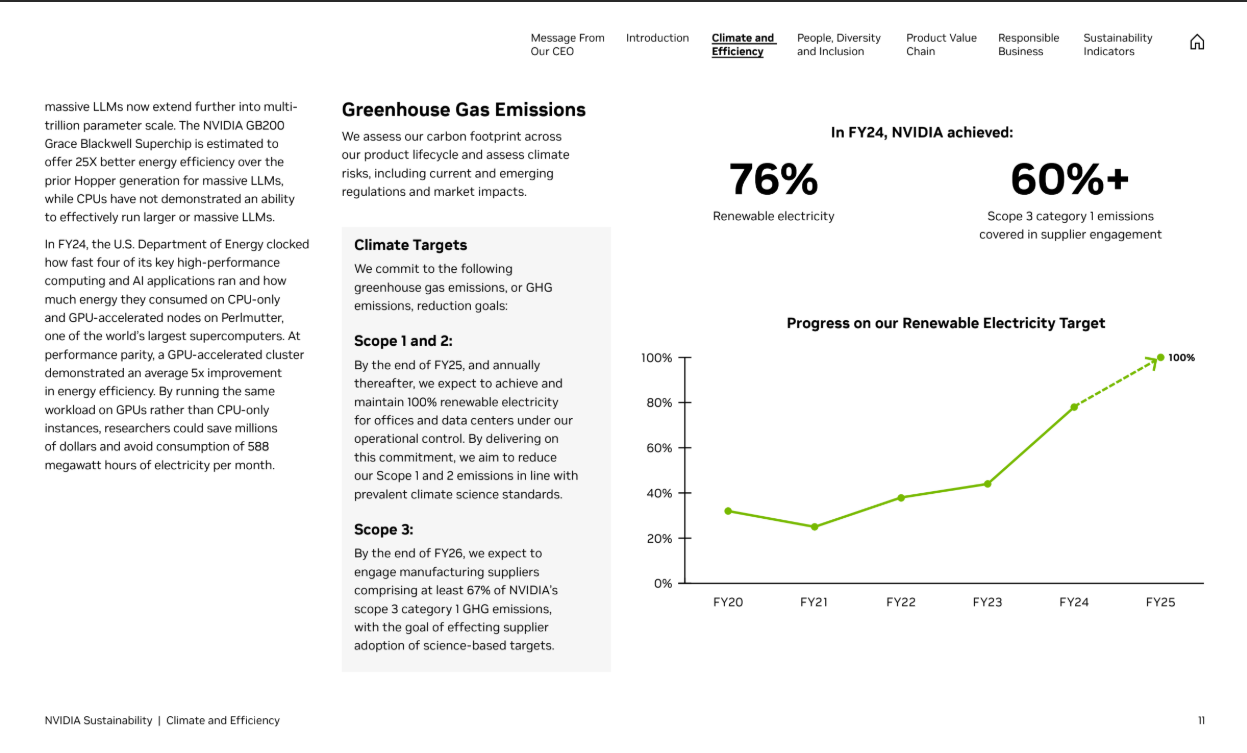
Using a limited amount of credits on the LlamaParse service, I managed to see improved recall on a subset of difficult documents ( NVDA 2024 and AAPL 2024) recall from 0.4 to 0.8 with no precision loss. However, with no budget to speak of for this service, I tried an alternative approach of using an LLM calls to double-check and clean up the extracted text on selected pages with the presence of text strings related to climate targets, which led to modest improvements but nothing close to the performance of LlamaParse (recall = 0.8036, precision = 0.8052, f1 = 0.8041).
The experimental loop enabled me to cycle through ideas quickly, eliminating paths that would have had a high reward-to-cost ratio but proved unsatisfactory. In general, it was very easy to improve recall at the cost of precision. Most false negatives were caused by underpredicting scored targets, producing no prediction at all or labelling valid items as non_target_claim and false positives were often created by duplicate targets creeping through when precision guardrails were relaxed Therefore, I successfully managed modest gains through a semi-automated process while learning at a very fast rate.
Next Steps #
The experimental process here accelerated the rate of discoveries considerably and allowed me to learn about what mattered meaningfully and what did not. As a result, even though I did not hugely increase performance, I am left in a very good position to conduct further experiments that I believe would make a large difference.
I would place priority on improving the conversion of PDFs to text-formats that can represent layout better without encoding issues. As mentioned, LlamaParse exhibited an immediate boost in recall on the two most difficult sets of company-year documents. I am hampered by the lack of a local GPU, along with a very low budget for cloud-based platforms, meaning that many newer LLM-based approaches, such as Docling were out of reach for this round of experimentation. However, I would look to prioritise changing this for the next round. Following that, I would examine a more “structurally aware” form of segmenting the documents into nodes, which entirely depends on the PDF conversion process retaining the layout in a consistent and accurate way.
I have used OpenAI’s embedding model so far, which no longer provide state-of-the-art performance. Trying alternatives might result in better performance. Furthermore, a more sophisticated re-ranker might also give significant improvements.
Repository #
You can find the code here: